| Sun, 15 Jun 2025 17:44:29 -0500 Yom Rishon, Chodesh Shlishi 18, 6025 — יום ראשון חדש שלישי יח ו׳כה |
|
|
|
Leningrad Codex Hebrew
JPS 1917 English Tanakh! |
| KETIV–QERE Variants |

|
בְּרֵאשִׁ֖ית בָּרָ֣א אֱלֹהִ֑ים אֵ֥ת הַשָּׁמַ֖יִם וְאֵ֥ת הָאָֽרֶץ׃ |
ACCENTS |
The Vowels and Accents,
plus the Maqqef (Dash–Like Character Aligning At Top Of Chars
(־) )
and Sof Pasuq (Colon–Like Character,
Designating End–Of–Verse (׃) )
are displayed on the consonants.
|
|
בְּרֵאשִׁית בָּרָא אֱלֹהִים אֵת הַשָּׁמַיִם וְאֵת הָאָֽרֶץ׃ |
VOWELS |
The Vowels plus the Maqqef and Sof Pasuq are displayed on the consonants. |
|
בראשית ברא אלהים את השמים ואת הארץ׃ |
CONSONANTS |
Only the Consonants are displayed (with Maqqef's and Sof Pasuq's). |
|
בְּ/רֵאשִׁ֖ית בָּרָ֣א אֱלֹהִ֑ים אֵ֥ת הַ/שָּׁמַ֖יִם וְ/אֵ֥ת הָ/אָֽרֶץ׃ |
MORPHOLOGY |
The Vowels and Accents,
plus the Maqqef and Sof Pasuq are displayed
on the consonants.
|
| תנך (תורה – נביאים – כתובים) |
|
Tanakh
(Torah - Nevi'im - Ketuvim) |
| Book Order Follows The Leningrad Codex Order! |
| תורה – Torah (The Five Books of Moses) | ||||
|---|---|---|---|---|
| BOOK | ACCENTS | VOWELS | CONSONANTS | MORPHOLOGY |
| Genesis — בראשית | Genesis | Genesis | Genesis | Genesis |
| Exodus — שמות | Exodus | Exodus | Exodus | Exodus |
| Leviticus — ויקרא | Leviticus | Leviticus | Leviticus | Leviticus |
| Numbers — במדבר | Numbers | Numbers | Numbers | Numbers |
| Deuteronomy — דברים | Deuteronomy | Deuteronomy | Deuteronomy | Deuteronomy |
| כתובים – Ketuvim (Writings) | ||||
|---|---|---|---|---|
| BOOK | ACCENTS | VOWELS | CONSONANTS | MORPHOLOGY |
| 1 Chronicles — דברי הימים א | 1 Chronicles | 1 Chronicles | 1 Chronicles | 1 Chronicles |
| 2 Chronicles — דברי הימים ב | 2 Chronicles | 2 Chronicles | 2 Chronicles | 2 Chronicles |
| Psalms — תהלים | Psalms | Psalms | Psalms | Psalms |
| Job — איוב | Job | Job | Job | Job |
| Proverbs — משלי | Proverbs | Proverbs | Proverbs | Proverbs |
| Ruth — רות | Ruth | Ruth | Ruth | Ruth |
| Song Of Solomon — שיר השירים | Song of Songs | Song of Songs | Song of Songs | Song of Songs |
| Ecclesiastes — קהלת | Ecclesiastes | Ecclesiastes | Ecclesiastes | Ecclesiastes |
| Lamentations — איכה | Lamentations | Lamentations | Lamentations | Lamentations |
| Esther — אסתר | Esther | Esther | Esther | Esther |
| Daniel — דניאל | Daniel | Daniel | Daniel | Daniel |
| Ezra — עזרא | Ezra | Ezra | Ezra | Ezra |
| Nehemiah — נחמיה | Nehemiah | Nehemiah | Nehemiah | Nehemiah |
|
|

|
| THE LENINGRAD CODEX |
|
FROM: https://www.jewishvirtuallibrary.org/the-leningrad-codex : Let us say on the outset that the Leningrad Codex is one of the most important Hebrew documents extant, with ramifications and influence that is immeasurable. It is -- along with the other famous biblical codex, the Aleppo Codex -- one of the sources for biblical tradition, for the study of Hebrew Scriptures, and for providing an accurate text for the reading and writing of the Torah and the other books of the Bible. The Leningrad Codex is the oldest complete manuscript of the Tanakh, the 39 books of the Bible. Written in Cairo on parchment in the year 1009 (the date appears on the manuscript), it is inextricably bound up with the Aleppo Codex, which is about a century older but undated. Moreover, the Aleppo Codex, housed for many years in the Aleppo Synagogue in Syria, was badly damaged in a fire during anti-Jewish riots in Syria in 1947, and so it is incomplete. The Aleppo Codex, now safely stored at the National Hebrew Library in Jerusalem, along with the Leningrad Codex, set the standard for the correct text of the Tanakh, including its vocalization and the musical accents (trop or te'amim) that accompany every word. Although the spelling of a word may be consistent in Hebrew, in the absence of vocalization (more commonly called the vowel "dots"), there can be variations as to how the letters are pronounced. Take the letters s, f, r, for example, which can variously be read as sefer, sapar (nouns), siper, safar, saper (verbs). The Leningrad Codex is a fully vocalized biblical text, assuring correct pronunciation of each word. Moreover, it contains all the accent marks (te'amim) above and below the letters. These accent marks almost miraculously serve three disparate functions: a) they are notes for cantillation of the word; b) they show the part of the word that should be stressed or accented; c) they serve as marks for phrasing and punctuation. It should be noted that the handwritten Torah scroll has only the letters of the words and no vowels points or other marks, for no vocalization of the text or trop are permitted on the Torah parchment. Hence, the importance of a fully vocalized manuscript like the Leningrad Codex, which follows a tradition that goes back nearly 2,000 years to Tiberias, in the land of Israel. By virtue of its existence, then, this Codex is the guide for all future handwritten Torahs and printed editions of the Bible. The Leningrad Codex is part of the Abraham Firkovich collection at the Russian National Library in St. Petersburg (formerly Leningrad), where it has been for more than 130 years. Firkovich was a Jewish businessman, a devoted Karaite (Jews who follow only the Bible and reject oral or Talmudic tradition), an inveterate traveler and collector of Hebrew manuscripts. The Codex was acquired by Firkovich (who offered no details in his letters or in his autobiography as to where he got it) and then sold it to the then St. Petersburg Imperial Library. It has been known for years that this important Codex was in the great library in Leningrad, which also houses hundreds of other priceless Jewish manuscripts. In 1990, under Gorbachov's glasnost, and after much delicate negotiations (including giving the library photographic equipment and a fax machine), the library permitted foreign photographers to come and photograph this rare document for the first time. |
|
|
| TRANSLATION / PUBLICATION NOTES |
|
|
| TANAKH (HEBREW SCRIPTURE PASSAGES) |
|
Leningrad Codex Based Tanakh (aka Hebrew Scriptures) derived from:
NOTE: Those of us who have benefitted from the great work done by the J. Alan Groves Center For Advanced Biblical Studies owe a huge debt of gratitude for their (no doubt) extremely tedius, careful, monumental efforts in creating the Westminster Leningrad Codex. |
|
|
| ENGLISH SCRIPTURE PASSAGES : |
|
"The Holy Scriptures, Tanakh 1917 edition (JPS 1917)" The Holy Scriptures, Tanakh 1917 edition (JPS 1917), is in the public domain. Although descriptions of the JPS 1917 Tanakh claim that it is based upon The Masoretic Text (aka The Leningrad Codex), as a matter of fact, that, at least for the rendering of the 10 Commandments in Exodus 20 and Deuteronomy 5, the actual Verse numbering DOES NOT correspond to the Masoretic Text! For this edition of The-Iconoclast.org's Hebrew–English Tanakh, I have set both 10 Commandments passages to match that of the Leningrad Codex (aka The Masoretic Text). Additionaly, I changed the English interpretation for Exodus 20:5 and Deuteronomy 5:11, which I feel better expresses the actual Hebrew text (for more information, please see my page https://www.the-iconoclast.org/reference/ComparisonExodus20_Deuteronomy5InLeningradCodex.php).
Rabbinic Orchestrated Shavuot Confusion:
The Morrow After The Shabbat (not – 'after the day of rest')! I also changed the phrase in Leviticus 23:15, "from the morrow after the day of rest", to "from the morrow after the sabbath", which is the literal translation of the Hebrew text. This also helps prevent the false interpretation of rabbis which forces the counting of the Omer to begin on the second day of the feast of unleavened bread (the rabbis interpret the first day as a 'High Sabbath' and apparently confuse that with the regular weekly Sabbath), rather than "from the morrow after Sabbath", the natural interpretation that explicitly states that the counting of the Omer begins on the next "first day of the week", the day following the weekly Sabbath in the week containing the feast of unleavened bread (the non–forced, plain meaning of the Hebrew)! |
|
|
| The Name יְהֹוָה [Yehovah] |
|
יְהֹוָה
[Yehovah]: The Name Of G-d In The Hebrew Scriptures
("YHVH":
י
'Yud',
ה
'He',
ו
'Vav',
ה
'He', aka the Tetragrammaton)
Is Used Instead of "LORD" in the phrases "the LORD", "The LORD",
and "O LORD" In The Original JPS 1917 Tanakh.
In Converting "LORD" to "Yehovah", I Counted A Total Of 5,553 Occurrences In The JPS 1917 Tanakh! |
|
|
| הָאָדֹ֥ן ׀ יְהוָֽה [ha Adon Yehovah] |
| The Hebrew Phrase הָאָדֹ֥ן ׀ יְהוָֽה Occurs In Only Two Places: In Exodus 23:17 and 34:23. In Those Cases, I Have Changed The Translation Wording From "Lord GOD" To "Lord GOD [ha Adon Yehovah]". |
|
|
| אֲדֹנָ֥י יְהֹוִֽה Adonai Yehovi |
|
Typically Translated As "Lord GOD",
It Is A Much Less Common Form Of The Divine Name
יְהֹוָה)
[Yehovah]).
This Form Is, Nevertheless, Quite Important In Understanding Pronounciation,
Especially Since The Hebrew Form For It (As Well As Its English Translations)
Has NOT Undergone The Intense Scrutiny Of Censorship As Has "Yehovah"!
In Converting "Lord GOD" to "Lord GOD [Adonai Yehovi]", I Counted A Total Of 284 Occurrences In The JPS 1917 Tanakh. Of All Of Its Occurrences, The Fully Voweled Form Of The Hebrew אֲדֹנָ֥י יְהֹוִֽה Appears 31 Times, And The Non–Fully Voweled Form אֲדֹנָ֥י יְהוִֽה (The Same Hebrew Letters, Minus Just The One 'Oh' Sounding Character, "The Holem", Which Follows The First 'He' In י 'Yud', ה 'He', ו 'Vav', ה 'He'), Make Up All Other Occurrences. |
|
|
| תורה Torah |
|
The Word "law" As Found In The JPS 1917 Has Been Changed To
"Torah" In All Places Where The Root Hebrew
תורה
(TORAH) IS IN THE CORRESPONDING LENINGRAD CODEX TEXT!
In Converting "Law" to "Torah", I Counted A Total Of 223 Occurrences In The JPS 1917 Tanakh! |
|
|
|
City Of "Jerusalem"
Yerushalam, Yerush'lem and Yerushalayim |
|
יְרוּשָׁלִַ֖ם Yerushalam |
|
The Word "Jerusalem" (the name of capital city in ancient Israel),
As Found In The JPS 1917, Has Been Changed To Its Transliterated Equivalent,
"Yerushalam" (note the 'am' ending),
In All Places Where It Corresponds To The Hebrew
[יְרוּשָׁלִַ֖ם]
.
|
| יְרוּשְׁלֶֽם Yerush'lem |
| A Rare Second Transliterated Form, "Yerush'lem" (note the 'em' ending), Has Been Changed From "Jerusalem" Where The Hebrew Letters Spell Out The Aramaic Form [יְרוּשְׁלֶֽם] Found In Aramaic Parts Of Daniel And Ezra. |
| ירוּשָׁלַ֙יִם֙ Yerushalayim |
|
The Extremely Rare, Third Transliterated Form, "Yerushalayim"
(note the 'ayim' ending),
Has Been Changed From The JPS 1917 "Jerusalem" To Correspond To The Hebrew
[ירוּשָׁלַ֙יִם֙].
Noteworthy Is That This Rarest Form Appears In Only Four (4) Places In The Entire Hebrew Scriptures, Yet, It Is The Most Common Pronunciation For The Name Of The Ancient City! Its Four (Out Of Over 600) Occurrences Are: 1) Jeremiah 26:18, 2) Esther 2:6, 3) I Chronicles 3:5, and 4) II Chronicles 25:1. In Converting "Jerusalem" To Its Transliterated Equivalents, I Counted A Total Of 625 Occurrences In The JPS 1917 Tanakh! |
|
|
| בִּלְעָ֔ם Bilaam |
|
The Name "Balaam" As Found In The JPS 1917 Has Been Changed To
"Bilaam" In All Places Where The Root Hebrew
בִּלְעָ֔ם
(Bilaam) IS IN THE CORRESPONDING LENINGRAD CODEX TEXT!
In Converting "Balaam" to "Bilaam", I Counted A Total Of 55 Occurrences In The JPS 1917 Tanakh (53 in Numbers, 2 places in Deuteronomy)! |
|
|
|
QERE
—
KETIV
(What is Read —What is Written) : |
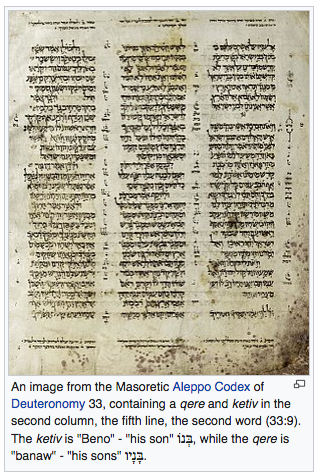
Qere and Ketiv, from the Aramaic qere or q're, קְרֵי ("[what is] read") and ketiv, or ketib, kethib, kethibh, kethiv, כְּתִיב ("[what is] written"), also known as "keri uchesiv" or "keri uchetiv," refers to a system for marking differences between what is written in the consonantal text of the Hebrew Bible, as preserved by scribal tradition, and what is read. In such situations, the Qere is the technical orthographic device used to indicate the pronunciation of the words in the Masoretic text of the Hebrew language scriptures (Tanakh), while the Ketiv indicates their written form, as inherited from tradition. SOURCE: https://en.wikipedia.org/wiki/Qere_and_Ketiv |
|
Q. What is the Qere and Ketiv and how does it relate to the Masoretes?
( see: http://jbtc.org/v08/Graves2003.html ) For PDF Of Above Link Click This Line! A. Qere and Ketiv are orthographic devices that were used by the Masoretes, i.e., Jewish scribes from the 6-10th centuries. Qere means, "what is read," and ketiv means, "what is written". It is found in existing Masoretic manuscripts dating to the 9th and 10th centuries, CE. There are several forms of Qere / Ketiv, including: ordinary, vowel, omitted, added, euphemistic, split, and qere perpetuum. The ketiv that is most relevant is the vowel qere. In this case, the consonants are unchanged, but different vowel signs are added and only the qere, i.e., what is read, is vocalized. ... |
|
|
| PLEASE NOTE: I Challenge The Rabbinic QERE–KETIV System! |
|
In January 2022, I completed work I had initiated in October 2021 to change the
QERE–KETIV
order to make KETIV to be prominent and diminish the
QERE. Thus, this would make the text conform to
the Masoretic original (Leningrad Codex) before those coming after (ok, the rabbis)
decided "they knew better" and wanted to change over 1100 words. Notably,
those Jewish Publishers who assembled our Tanakhs (Hebrew Jewish Scriptures)
chose to preserve the rabbinic
QERE–KETIV
system, so they made adjustments to their Hebrew texts to ensure that the
QERE would predominate whenever the text was read!
To that end, the Stone Edition of the Tanakh places the QERE before the KETIV, which they put in brackets, making it so that the reader automatically sees the QERE and only with difficulty will look at the bracketed KETIV (what was actually written). Similarly, Koren Publishers place the Ketiv in the column to the right of the sentence and the unvoweled QERE within the Hebrew text itself. It might be said that Jewish Publishers "could have cared less" in their efforts to amount to what is Adding or Taking Away From Scripture (The Word of God) as found in Deuteronomy 4:2, Deuteronomy 13:1 (Christian Bibles: Deuteronomy 12:32), Proverbs 12:6; in the Christian New Testament book of Revelation 22:18-19! |
| The New KETIV–qere Hebrew Rendering (ACCENTS)! | Thus, this current version uses the Ketiv, what is written, as the predominant rendering, while making the Qere, what the "rabbis" have commanded as Must Be Read instead, to be a minimalist secondary format (much as rabbis appear to have intended the Ketiv to be!). |
|
One of the reasons I decided to take on this new rendering effort is that in
my efforts to understand the nature of the rabbinic
Qere–Ketiv system
I have not truly found a satisfactory explanation of why the
"Qere" should always
take precedence over the
"Ketiv" in reading the Tanakh.
In fact, as I understand it, rabbinic "scribes", in examining the actual Aleppo and Leningrad Codices, appear to have taken upon themselves to adding the consonant only Qere in the margins upon the original manuscripts, where, in their "infinite wisdom" they have presumed themselves to be the greater authority! Moreover, as rabbinic sources seem to indicate that the "Ketiv" should never be uttered, I have found instances, such as in Exodus 21:8, where I believe the "Qere" is blatantly INCORRECT — and that the "Ketiv" should be the preferred "reading", as if the Masoretes actually knew what they were doing all along! In my own regular Scripture reading (Stone Edition Tanakh–Larger Text version), my preference has been to read the "Ketiv" (what is written) and pretty much minimize the "Qere"! This is not easy to do because the predominant Qere is rendered as if it is the normative form, and the Ketiv follows, within brackets, as if it is the offensive variant (in the Stone Edition Tanakh)! Again, in the Koren Publications Tanakh, the "Ketiv" is what is rendered in the margin, while the "Qere" is found in the regular text! Obviously, normal reading will typically ignore what the Masoretes wrote, the "Ketiv"! As of January, 2022, I have updated all 39 books of Jewish Scriptures in the "ACCENTED" edition found herein ("ACCENTS" matches Masoretic text containing vowel pointers and Trop marks) of The-Iconoclast.org online Tanakh. I consider this as to convey the intent of the Masoretes. However, I acknowledge that rabbis (talmudists) have expended much effort to obscure the written Torah as part of their regular practice; as they appear, to me, to view themselves collectively as אֱלֹהִ֔ים Elohim. That is, I believe that those talmudists (rabbis), consider themselves collectively to be God!!! They certainly demand that their edicts (tachanot) are followed as if they are divinely inspired law! If you find this information of interest and want to see any or all of the over 1100 KETIV–qere variants, please view the page on KETIV–QERE Variants. |
|
|
|
|
|
THE TEN COMMANDMENTS
IN EXODUS 20 AND DEUTERONOMY 5 ADJUSTMENT TO VERSES TO CONFORM TO ACTUAL LENINGRAD CODEX!!! : |
|
For More Information On Exodus 20,
See the Page: Exodus 20 In The Leningrad Codex For More Information On Deuteronomy 5, See the Page: Deuteronomy 5 In The Leningrad Codex NOTE: Both the Westminster Leningrad Codex (WLC) Hebrew and JPS 1917 English texts were modified in The-Iconoclast.org's Hebrew—English Tanakh to conform to the actual verse ordering found in the Leningrad Codex for Exodus 20 and Deuteronomy 5! Neither in the WLC nor in any other Jewish or Christian source, that I have reviewed or am aware of, adhere to the original source in the Hebrew of the Leningrad Codex (Except The-Iconoclast.org's online Tanakh)!!! HEBREW TEXT FOR THE TEN COMMANDMENTS The Hebrew Text For both Exodus 20 and Deuteronomy 5 Has Been Corrected To Correspond To The Actual Facsimile Text Of The Leningrad Codex, Matching The Verse Ending SOF-PASUQ Symbol (LOOKS LIKE A HEAVY COLON [ : ]) At The End Of A Verse. ENGLISH TEXT FOR THE TEN COMMANDMENTS "The Holy Scriptures, Tanakh 1917 edition (JPS 1917)" English Text Verses Have Likewise Been Adjusted To Correspond To The Verse Order Of The Hebrew Text Of The Leningrad Codex (aka Masoretic Text). |
|
|
|
Multi–Wide Unicode Encoding Conversion
Of The Westminister Lenigrad Codex (WLC) And HTML Formatting For The Web |
|
I want to reiterate my appreciation for what I consider to be
"monumental" efforts of the
J. Alan Groves Center For Advanced Biblical Studies in creating the
digitized version of the Leningrad Codex (Westminster Leningrad Codex – WLC).
That effort made it possible for me to "programmatically" convert the
Multi–Wide Unicode Encoded Hebrew text of the "Westminster Leningrad Codex"
for which I used to assemble the
The-Iconoclast.org's Hebrew–English Tanakh.
It should be noted that at the J. Alan Groves Center For Advanced Biblical Studies, they have posted that "in 2020" they will be introducing a Unicode based Tanakh. However, as of October 2020, I am not aware that such a document has been published. Therefore, I took it upon myself to convert existing documents (in two distinct and different formats) from https://www.tanach.us which, at this time, still hosts the work of the J. Alan Groves Center For Advanced Biblical Studies. |
|
|
| QERE (Consonants Only) – KETIV (Vowels and Trop) |
|
Prior to October, 2020, my original effort was to take the
(WLC) Multi–Wide Unicode Encoded Hebrew Text (in the table section,
choosing the "zip" resources for "TEXT" such as
"tanach.mor.txt.zip") and Converting
it to my Hebrew Font Encoding For Web Pages. In that effort,
I also had taken that new Web Page Encoding and transposed
the Ketiv–Qere
order to make for a the Qere
(what is read)
to be inconsequential (the lesser). This itself was a huge programming effort,
requiring the identification of no less than 15 different patterns
in the production of that version of The–Iconoclast.org Hebrew–English Tanakh.
It may be noted that within the structure of the WLC, the
Qere–Ketiv patterns
were designated by a single or double asterick within pattern groups; due to the complex
nature of attempting to correctly collect the data, I had not been able to
create a truly 100% correct rendering (although I was close!).
In October, 2020, I decided to use a differently formatted source found at www.tanach.us (when clicking on one of the Books, in the next page selecting the HTML for the text) to render the Qere–Ketiv in the same manner done for the WLC. I still had to convert the Multi–Wide Encoded Unicode Hebrew to Web Hebrew, but extracting the Qere–Ketiv, within the Hebrew, though still a challenge, was such that I am confident that that rendering was correct. I did take the HTML formatted Qere–Ketiv and replaced the letters/numbers with images as I found in my reproduction the raw HTML was, for lack of better phrasing, "squirrelly"! |
|
|
| C++ Programming Language Used For Conversion/Manipulation | Written In C++ Programming Language By Robert M. Pill (continuation of work begun in 2005 (written in Java), to parse variant font encodings). Copyright © 2005–2021 by Robert M. Pill, All Rights Reserved. |
|
Note: Hundreds of programming hours were needed in my initial efforts
to take the
(WLC) Multi-wide Unicode text and convert it to standard
Web Page Encoding; and then transposing the WLC Qere–Ketiv,
where there are at least 15 variant patterns to conform
to normative Jewish sourced Tanakh's (where the "Qere" is
the preferred "reading"). As noted above, I took
WLC HTML (Multi–Wide Unicode Hebrew) formatting
to convert it to Web Hebrew and replace HTML based references to the Groves
Notes with actual images of their corresponding letters and or numbers.
It should be noted that the Multi–Wide encoded Unicode, as in the sourced Westminster Leningrad Codex electronic version, is very tricky to work with. Even if you can open the text file or html file in an editor, and when you think you are deleting a certain Multi–Wide Unicode formatted character, a different character several positions removed will typically be the one affected! In short, suffice it to say that working with Multi–Wide encoded Unicode is similar to "HERDING CATS!!!".
Modifications Necessary To Correspond To Actual Leningrad Codex!
As noted above, both the Westminster Leningrad Codex (WLC) Hebrew and JPS 1917 English texts were modified to conform to the actual facsimile PDF File of the Leningrad Codex for Exodus 20 and Deuteronomy 5. To date, I have not found any other source (Jewish or Christian), including the Westminster Leningrad Codex (WLC), that adheres to the structured order of the original Hebrew for the Ten Commandments as written by the Masroetes in the Leningrad Codex! In fact, The–Iconoclast.org Exodus 20 contains 21 verses; the JPS 1917 contains 22 verses; and the King James Version contains 26 verses! Regarding Deuteronomy 5, The Iconoclast.org version contains 31 verses; the JPS 1917 contains 29 verses; and the KJV contains 33 verses! In constructing The-Iconoclast.org Leningrad Codex based Tanakh, I felt it important to consider that the writers of the Codex purposefully rendered Exodus 20 and Deuteronomy 5 — The Two Passages Containing The Ten Commandments — as they did, and I wanted to respect that in my rendering. The original conversion of WLC Multi–Wide Encoded Unicode into Web Encoded Hebrew was completed on July 4, 2019. Completion of the transposing of that Web Encoded Hebrew for the Qere–Ketiv was completed on September 17, 2019. The current The–Iconoclast.org version was completed in October, 2020 (I modified the Hebrew verse numbering in May 2021). In it, I took the html version of the WLC, where I converted the Multi–Wide Encoded Unicode Hebrew to Web Hebrew, kept the order of the WLC Qere–Ketiv (note: the "accented" version reference is at https://www.tanach.us/Server.html?Exodus*). As with my original rendering, I took both the Hebrew and English texts and set them to match the actual Leningrad Codex for Exodus 20 and Deuteronomy 5. Originally, I had used the American Standard Version for the English text since I had previously set it up in a format that I could render for the Web (circa 2002). By July 2020, through additional programming I converted the JPS 1917 as provided by https://mechon-mamre.org (in htm (web) format), to that same format. That, with other original programming was used to create the present Westminster Leningrad Codex (WLC) based Hebrew Tanakh, and now the English based Jewish Publication Society version of 1917, with similar alterations to conform to the Masoretic text for Exodus 20 and Deuteronomy 5. |
|
|
| Hebrew Verse Numbering Changes For טו (15) & טז (16) |
|
In May, 2021, during the course of completing the writing of my book, "The Real God Code:
The Ten Commandments In The Leningrad Codex", I realized that in order to
be consistent I needed to change the Hebrew Verse Numbering for numbers
15 and 16 throughout the Tanakh.
The reason for this change is that rabbinic edict has determined that the numbers that would regularly be written with Hebrew letters for 15 and 16 would spell out parts of the Tetragrammaton (the 4 letter Hebrew Name for Yehovah). Moreover, as they forbid the saying of the Name יְהֹוָה [Yehovah], they also have forbidden even parts of that name in representing numbers using Hebrew letters. Because, as a (self–proclaimed) Karaite, I do not adhere to the dictates of the rabbis, I decided to forego the superstition of using טו for the number 15 and טז for the number 16. In their stead, for the entire Tanakh, I am now using יה for the number 15 and יו for 16 everywhere that verse numbering appears, doing away with the rabbinic numbering scheme of טו (tet-vav) and טז (tet-zayin), for numbers 15 and 16 respectively! |
|
|
| JPS 1917: Curly Braces In Text |
| Notes taken from Talk: Bible (Mechon-Mamre) |
| Regarding the single letters enclosed in curly "{" "}" braces these are from Mechon Mamre and indicate a number of things about the original Hebrew text as follows: "We [ Mechon Mamre] have added signs for the paragraphs found in the original Hebrew: In the poetical books of Psalms, Job (aside from the beginning and end), and Proverbs, each verse normallly starts on a new line; where there is a new line within a verse, we added {N}, and when there is a blank line, we added {P}. In the rest of the books, we added {S} for setumah (open space within a line) and {P} for petuHah (new paragraph on new line) according to our Hebrew Bible). We have not tried to reproduce the complex structure of the special songs such as in Exodus 15 and Deuteronomy 32, as we do not think that that would make sense in English." |
|
|
|
צַלְמָוֶת
Great Darkness |
|
17 verses in the Tanakh contain the Hebrew word
צַלְמָוֶת (pronounced Tzal-mah-vet).
In each of those verses, the Hebrew word
צַלְמָוֶת
is usually translated, into English, as "Shadow of Death".
However, according to Ernest Klein, in his great reference book, "A Comprehensive Etymological Dictionary of the Hebrew Language for Readers of English," צַלְמָוֶת (Tzal-mah-vet) means "Great Darkness". "Shadow of Death" would be the translation if the word was a compound word separated by a (־) which is pronounced "mah-qef". This is because צַלְ (Tzal), by itself, means "shadow"; and מָוֶת (Mah-vet), by itself, means "death"! THAT RESULTING COMPOUND WORD WOULD BE: צַלְ־מָוֶת. You may note that in the 17 verses below there IS NOT a ( ־ "maqqef") within the word צַלְמָוֶת which is, therefore, properly translated as "great darkness". |
|
Job 38:17 |
|||
| הֲנִגְל֣וּ לְ֭ךָ שַׁעֲרֵי־מָ֑וֶת וְשַׁעֲרֵ֖י צַלְמָ֣וֶת תִּרְאֶֽה׃ | יז | 17 | Have the gates of death been revealed unto thee? Or hast thou seen the gates of great darkness? |
|
Among those verses containing
צַלְמָוֶת,
Job 38:17 is a good illustration of the use of the
־ (maqqef) in another word, which is a compound word with a combining maqqef.
In that verse there is a compound word, שַׁעֲרֵי־מָ֑וֶת, translated as "gates of death"! This is an appropriate use of a maqqef and since it is in the same verse as a צַלְמָוֶת, it is easy to see the distinction, whether you insist in keeping previously understood translations of "shadow of death", especially in such iconic passages as Psalms 23:4, "The Lord is my shepherd, I shall not want ..." (see passage below)! |
| If that is not enough to help understand why I have made these changes, here is the definition of צַלְמָוֶת as given in Ernest Klein's aforementioned resource: |
|
צַלְמָֽוֶת m.n. great darkness. [According to the traditional pronunciation the word is regarded as compounded of צֵל and מָוֶת, hence lit. means ‘shadow of death’. However, most modern scholars read צַלְמוּת and derive the word from צלם ᴵᴵ.]
צלם ᴵᴵ to be dark. [Arab. ẓalima, Ethiop. ṣalma (= was dark). Base of צַלְמוֹן, possibly also of צַלְמָוֶת.] צַלְמוֹן m.n. MH darkness (in the Bible occurring only as the name of a mountain, Jud. 9:41, and Ps. 68:15). [Formed from צלם ᴵᴵ with ◌וֹן, suff. Forming abstract nouns.] |
|
For additional information on this topic, please see the page צַלְמָוֶת Great Darkness |
|||
|
|
|
As The-Iconoclast.org (WLC) Leningrad Codex
Hebrew—Modified JPS 1917 English Tanakh was
created programmatically (as mentioned above, using the C++ Programming
Language):
If Anyone Finds Any Errors, Please Notify Us By Clicking WebMaster To Email The Details! |
|
Site Last Updated:
Last Israel New Moon: Copyright © 2007–2025— Email WebMaster: |
June 12, 2025
2025-05-28 [3] Robert M. Pill WebMaster |